
Hôm nay mình thấy khá nhiều bạn mới tạo website và khi submit sitemap lên google thì gặp lỗi Url bị giới hạn bởi roboot.txt. Lỗi này thực ra rất dễ khắc phục, lỗi xảy ra nguyên nhân chủ yêu là do file robots.txt của các bạn bị sai cấu trúc. Hướng dẫn này áp dụng cho website sử dụng mã nguồn WordPress nhé. Các website dùng mã nguồn khác thì nó sẽ khác ở dòng Disallow.

Trước tiên chúng ta cùng tìm hiểu về khái niệm Robots.txt:
Robots.txt hay The robots exclusion protocol (REP) là một file text mà người quản trị web tạo ra để hướng dẫn robot (bọ tìm kiếm của công cụ tìm kiếm) làm thế nào để thu thập dữ liệu và index các post/pages trên trang web của họ. Nó là một nhóm các tiêu chuẩn web để điều chỉnh hành vi Robot Web và lập chỉ mục cho công cụ tìm kiếm. REP bao gồm những điều sau đây:
- REP xuất hiện năm 1994, trở nên phổ biến hơn năm 1997, dùng để xác định chỉ thị thu thập thông tin cho robots.txt. Một số công cụ tìm kiếm hỗ trợ phần mở rộng như mô hình URI (thẻ wild).
- Từ năm 1996, REP được mở rộng để xác định các chỉ thị chỉ mục (REP tags) để sử dụng trong các yếu tố meta robot, còn được gọi là “robot meta tag.” Khi đó, công cụ tìm kiếm hỗ trợ thêm thẻ REP với một
Tag-X-Robots. Người quản trị web có thể sử dụng REP tag trong tiêu đề HTTP của các nguồn tài nguyên không phải HTML như tài liệu PDF hoặc hình ảnh. - Từ năm 2005, phiên bản Microformat rel-nofollow để xác định xem công cụ tìm kiếm nên xử lý thế nào với các liên kết có thuộc tính REL của một phần tử chứa giá trị “nofollow.”
Những cũ pháp thông dụng trong File robots.txt
User-agent: Đối tượng bot được chấp nhận
Disallow/Allow: URL muốn chặn/cho phép
" * "Đại diện cho tất cả
Ví dụ: User-agent: * (Có nghĩa là chấp nhận tất cả các loại bot.)
Khóa toàn bộ site
Disallow: /
Chặn 1 thư mục và mọi thứ nằm trong nó
Disallow: /wp-admin/
Chặn 1 trang
Disallow: /private_file.html
Loại bỏ 1 hình từ Google Images
User-agent: Googlebot-Image
Disallow: /images/test.jpg
Bỏ tất cả các hình từ Google Images:
User-agent: Googlebot-Image
Disallow: /
Chặn 1 file hình bất kỳ, ví dụ .gif
User-agent: Googlebot
Disallow: /*.gif$
Những điều cần tránh trong file robots.txt
– Phân biệt chữ hoa chữ thường.
– Không được viết dư, thiếu khoảng trắng.
– Không nên chèn thêm bất kỳ ký tự nào khác ngoài các cú pháp lệnh.
– Mỗi một câu lệnh nên viết trên 1 dòng.
Cách tạo và vị trí đặt file robots.txt
– Dùng notepad tạo file, sau đó đổi tên file là robots.txt.
– Đặt ở thư mục gốc của website. (http://domain.com/robots.txt)
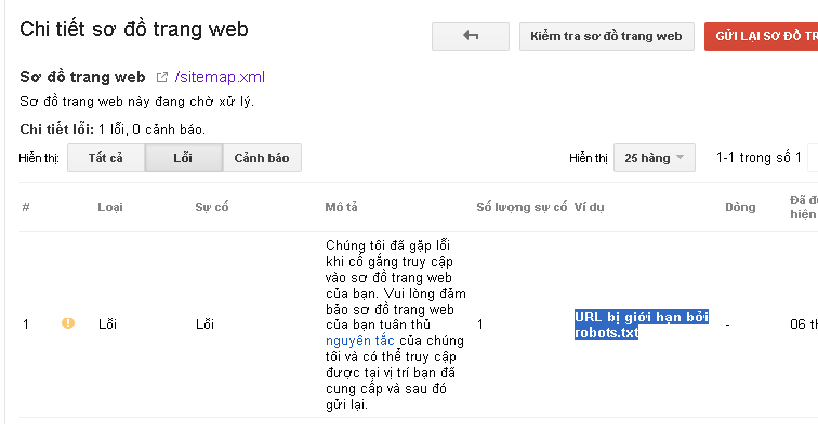
Như vậy qua các khái niệm và cấu trúc ở trên thì các bạn đã biết mình sai ở chỗ nào và tầm quan trọng của file robots.txt. Bây giờ mình sẽ hướng dẫn sửa lỗi Url bị giới hạn bởi roboot.txt.
Các bạn mở file robots.txt lên và thay toàn bộ code trong đó bằng đoạn mã sau:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /search?q=* Disallow: *?replytocom Disallow: */attachment/* Sitemap: http://domain.com/sitemap_index.xml
Sau đó các bạn thay http://domain.com/sitemap_index.xml bằng link tới file sitemap của bạn. Sau đó save lại là xong.
Chúc các bạn thành công!
Cảm ơn bạn rất nhiều
mình dùng website bằng mã nguồn wordpress nhưng không biết sửa file robots này ở đâu
Bạn muốn sửa nó thì trước hết bạn phải tạo nó ra đã nhé. Học tìm hiểu cách thêm robots.txt vào web trước đã nhé.
Không phải mặc định là nó có sẵn ạ bn,mình nghe trên diễn đàn nói là dùng plugin seo thì có sẵn nhưng mình không biết code không biết sửa
mai sẽ thử, mình nghĩ là ok. cảm ơn bạn